借助Fildder和Python实现手机app抓包爬虫,突破数据获取局限
在上一篇文章中,我们通过理论解释和三个爬网示例建立了相对完整的爬网知识框架。这三个示例的一个特征是它们都是网络侧爬网。本文使用软件和爬网程序来捕获移动应用程序上的数据包,因此该应用程序的数据并非隐藏!
目录
1。简介1。简介
它是HTTP协议调试代理工具,它可以记录和检查计算机和之间的所有HTTP通信,设置断点,并查看所有“ In in and Out”数据(参考HTML,JS,CSS和其他文件)。它比其他网络调试器更容易,因为它不仅揭示了HTTP通信,而且还提供了一种用户友好的格式。
简而言之,工作原理等同于代理。配置后,我们从移动应用程序发送的请求将被发送,并且服务器返回的信息将一次传输一次。因此,通过我们,我们可以看到该应用程序发送给服务器的请求以及服务器的响应。
2。结束配置
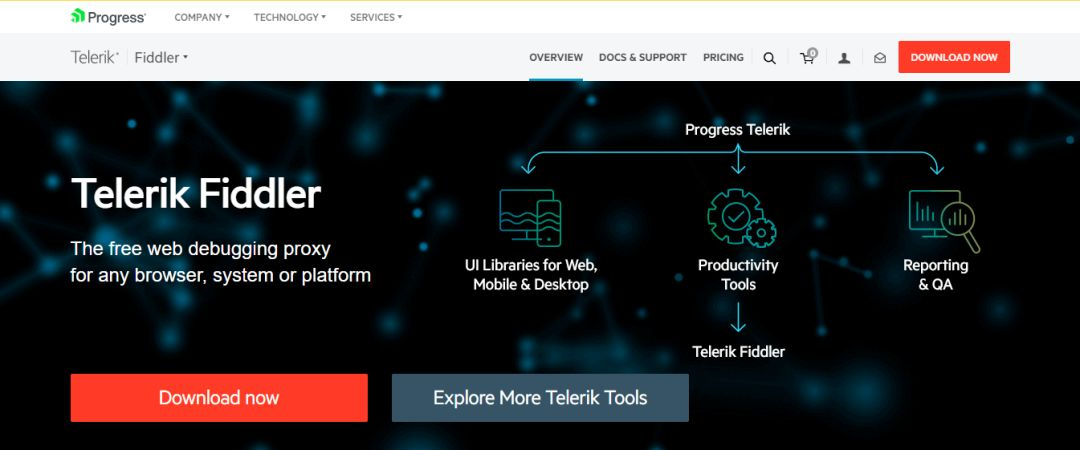
安装它后,首先在菜单工具>> HTTPS下选择这两个位置。
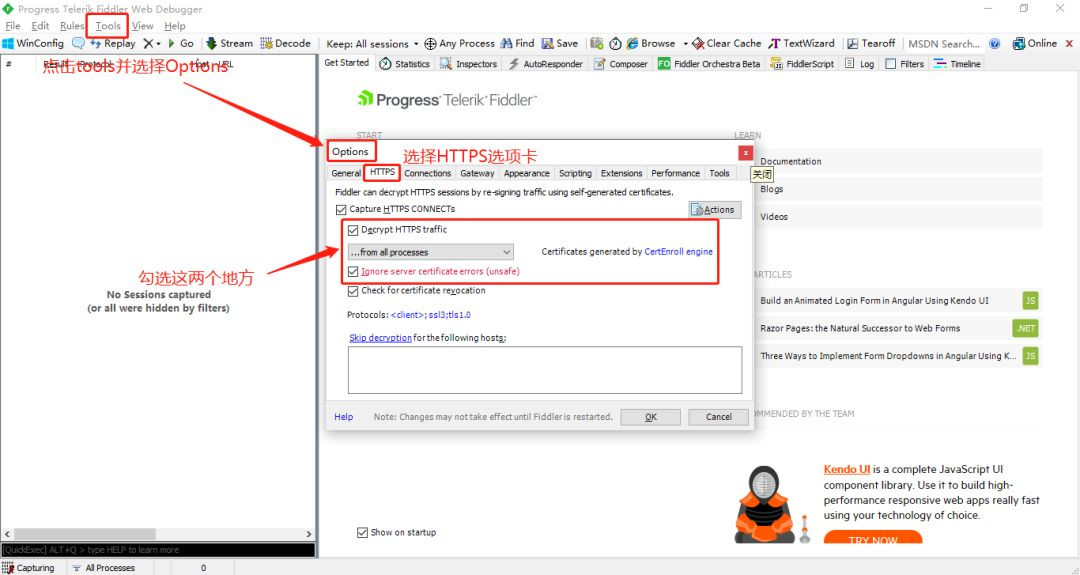
然后检查允许在选项卡下方,以允许其他设备的请求。
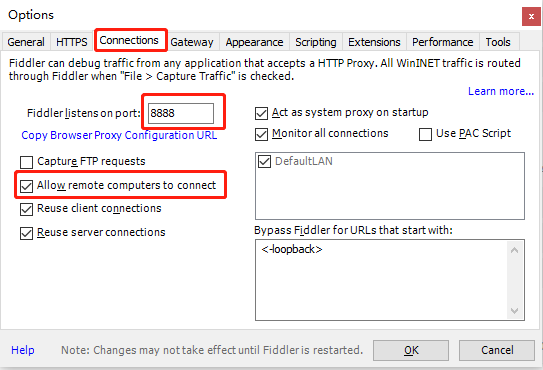
同时,请记住这里的端口号。默认值为8888。当时您需要在手机上填写它。配置完成后,保存后,必须将其关闭并再次打开。
3。手机配置
首先按WIN+R键输入CMD打开,输入命令以查看IP地址:
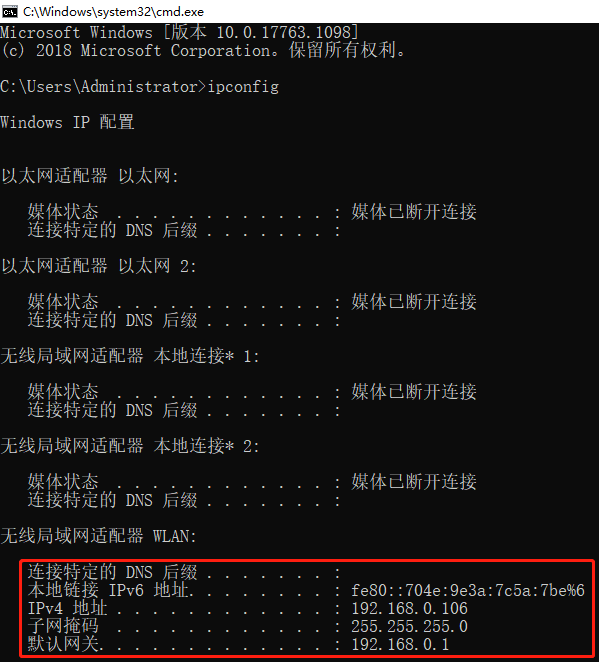
打开手机的无线连接,然后选择要连接的热点。按住长时间选择修改网络,然后填写代理代理中代理中的IP地址和代理端口。如下图所示:
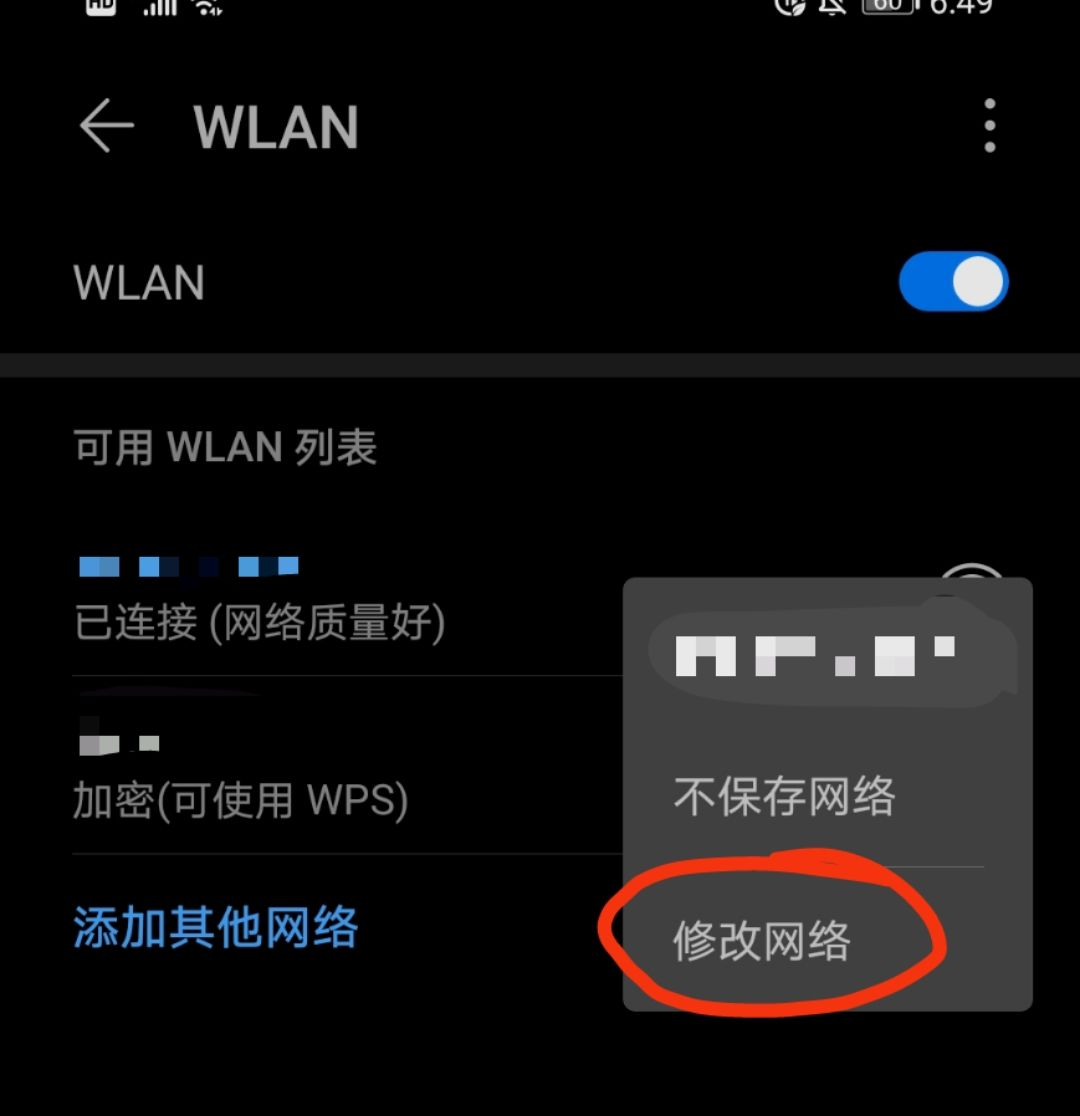
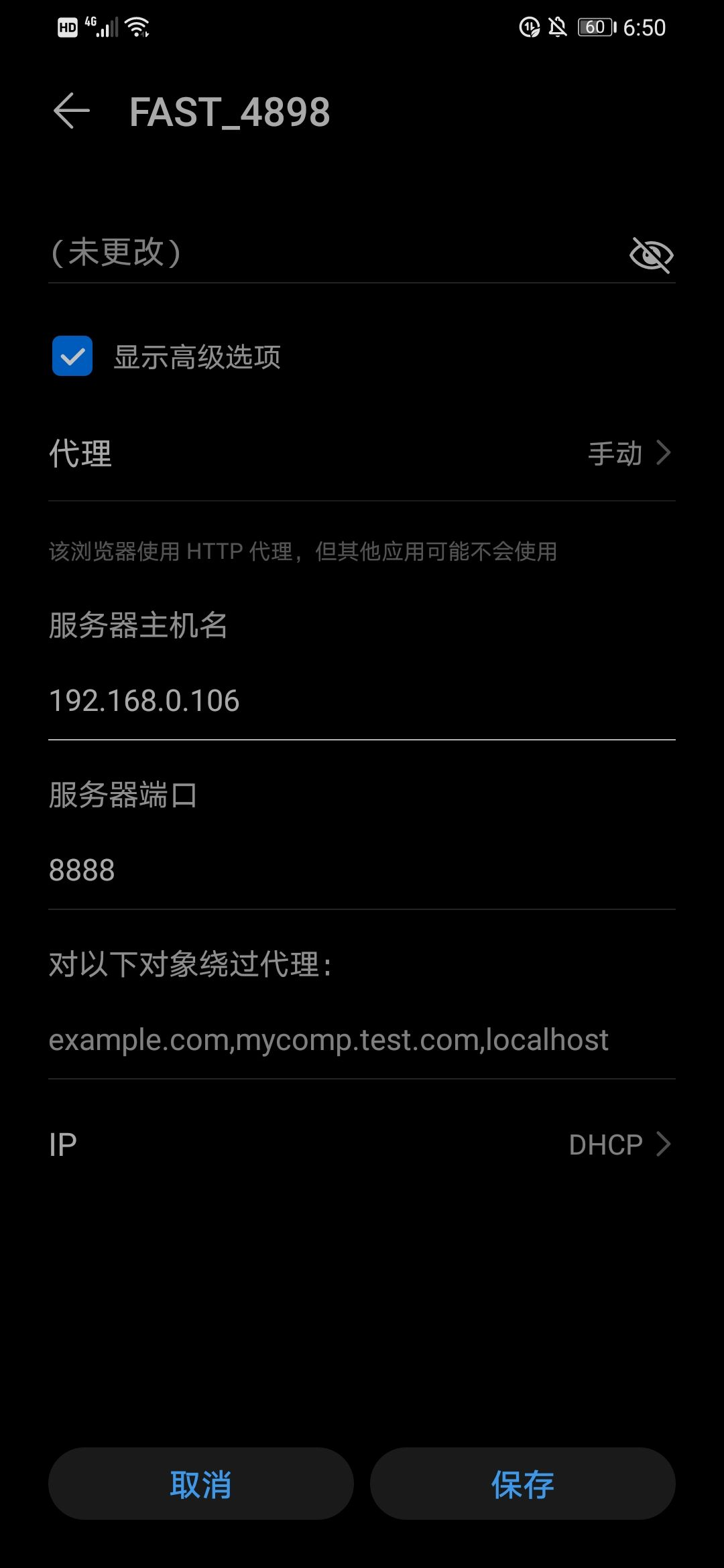
保存后,打开上述默认默认浏览器中的默认浏览器(即手机提供的浏览器)中的IP地址:8888(取决于您自己的情况)。
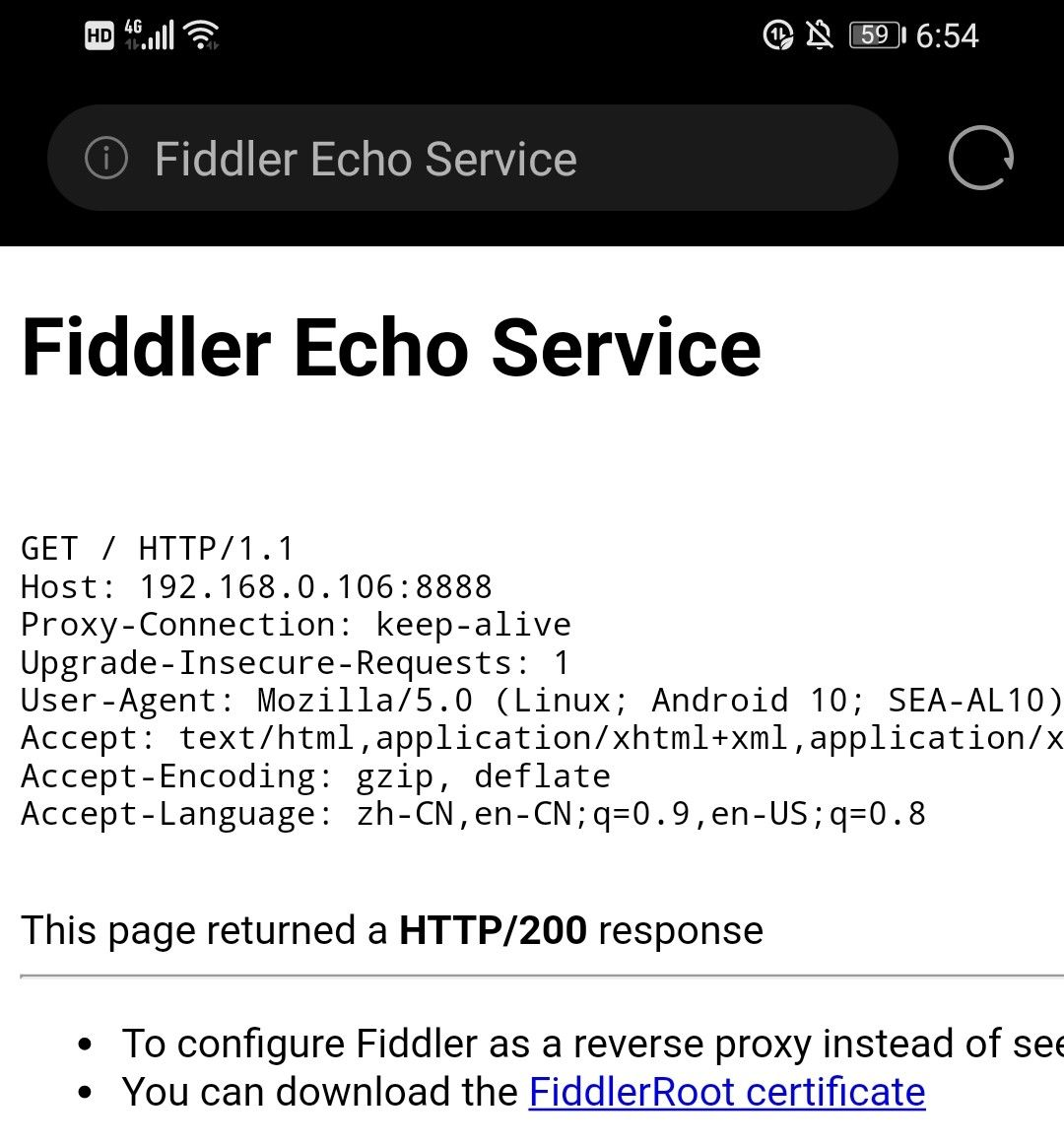
然后单击上面的蓝色链接,然后将其安装到您的手机上,以进一步使用计算机代理进行监视。
2。今天的 App软件包捕获练习1。源代码采集
首先,我们在上述配置环境下打开手机应用程序,并搜索“流行病”:
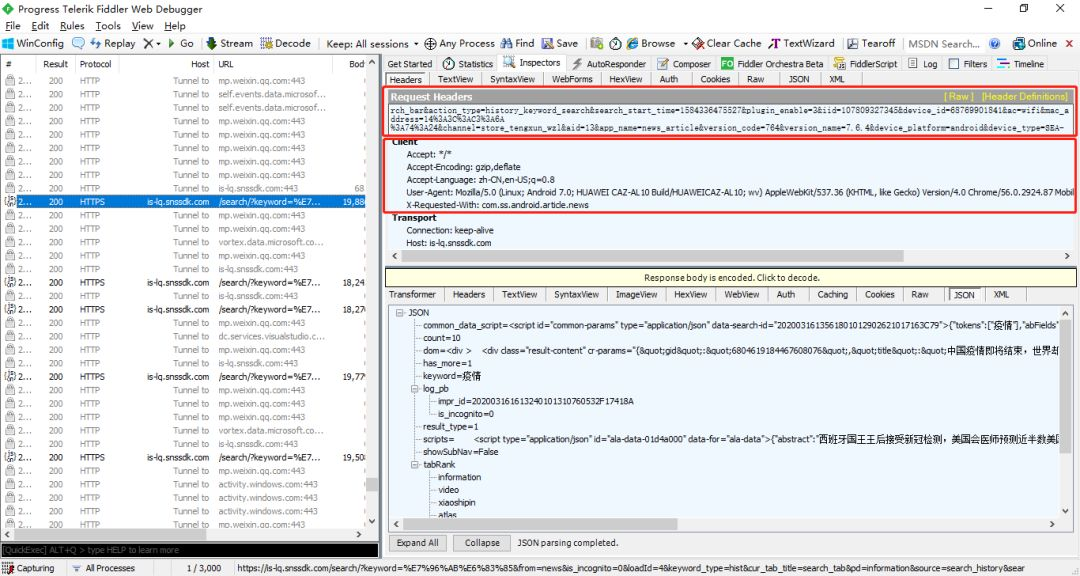
之后,您可以观察其中的许多弹出条目。通过观看和体验,发现与之相关的URL是我们想要的。双击此URL以进一步获取URL(即,我们的客户请求标题)
一点点整理您当前要求的代码:
import requestsimport timefrom bs4 import BeautifulSoupimport pandas as pdimport jsonimport randomfrom requests.packages.urllib3.exceptions import InsecureRequestWarningrequests.packages.urllib3.disable_warnings(InsecureRequestWarning)head = {'Accept': '*/*','Accept-Encoding': 'gzip,deflate','Accept-Language': 'zh-CN,en-US;q=0.8','User-Agent': 'Mozilla/5.0 (Linux; Android 7.0; HUAWEI CAZ-AL10 Build/HUAWEICAZ-AL10; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/56.0.2924.87 Mobile Safari/537.36 JsSdk/2 NewsArticle/7.0.1 NetType/wifi','X-Requested-With': 'com.ss.android.article.news'}url = "https://is-lq.snssdk.com/search/?keyword=..."req = requests.get(url=url, headers=head,verify=False).json()
2. json提取
接下来,我们的任务是分析响应json文件,通过req.keys()命令获取密钥信息,注意搜索,并发现文章的所有信息都包含在密钥的值中,并且该值是代码字符串,因此它通过库来解析:
soup = BeautifulSoup(req['scripts'],"lxml")contents = soup.find_all('script',attrs={"type":"application/json"})res = []for content in contents:js = json.loads(content.contents[0])abstract = js['abstract']article_url = js['article_url']comment_count = js['comment_count']raw_title = js['display']['emphasized']['title']title = raw_title.replace("","").replace("","")source = js['display']['emphasized']['source']data = {'title':title,'article_url':article_url,'abstract':abstract,'comment_count':comment_count,'source':source}res.append(data)
3。信息存储
提取相关文章信息后,您可以选择信息存储方法。我们通常使用JSON,CSV,XLSX和其他格式来存储它:
def write2excel(result):json_result = json.dumps(result)with open('article.json','w') as f:f.write(json_result)with open('article.json','r') as f:data = f.read()data = json.loads(data)df = pd.DataFrame(data,columns=['title','article_url','abstract','comment_count','source'])df.to_excel('article.xlsx',index=False)
4。自动爬行者建筑
最后一步是找到页面转规规则并完成自动化的轨道构造。我们又一手在搜索结果页面上滑下,找到继续弹出的URL。观察以下图片:
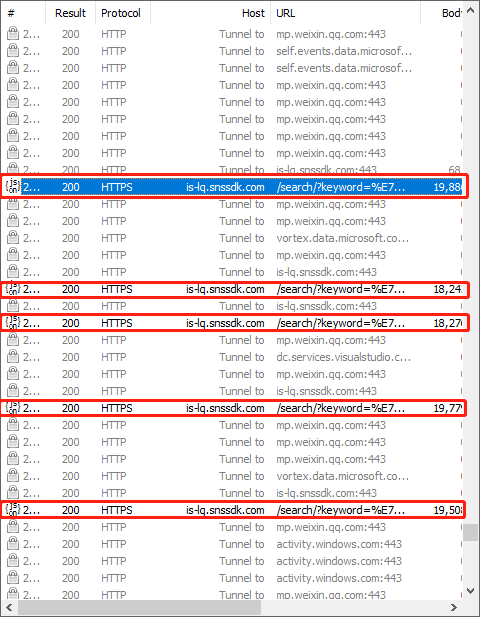
在观察这些URL之后,我们发现此参数只有差异,并且是10个倍数,因此我们的页面转循环代码是:
def get_pages(keyword,page_n):res_n = []for page_id in range(page_n):page = get_one_page(keyword = keyword,offset = str(page_id*10))res_n.extend(page)time.sleep(random.randint(1,10))return res_n
在这一点上,我们可以轻松地使用软件构建移动应用程序爬网程序,并将其与程序结合使用。然后,我们可以通过此轨道总结一下:首先,我们首先安装软件,并同时配置PC和移动代理,然后将其反馈到计算机上,以通过手机上的操作查看结果;然后判断数据包捕获结果要求的特定参数和数据格式,然后可以进一步处理和存储响应数据。结果如下:

可以通过在官方帐户中回复“ ”来获得搜寻器的完整代码。本文(上一篇文章)都在独立背景中爬行。爬行效率有限,定制成本很高。以下将进一步解释和实践分布式的爬行框架。上一篇文章中涉及的基本知识可以在下面找到:
网络爬网数据收集的实际战斗:基本知识
网络爬网数据收集的实际战斗:并重新库
网络爬网数据收集的实际战斗:电影爬行
Web爬网数据收集的实际战斗:网页分析库
网络爬网数据收集的实用战斗:汤加岛动态网页爬网
网络爬网数据收集的实用战斗:图书馆爬网JD产品
学习编号涉及数据分析和采矿,数据结构和算法,大数据组件和机器学习等。如果您关注并回复“学习材料”,您会感到惊讶〜

