数据分析实战:如何运用Pandas库进行足球运动员信息与技能水平的深度分析
数据意义
# inplace=True表示原地修改数据集
data.dropna(axis=0, inplace=True)
# 对删除后缺失值后的数据集,再次进行缺失值统计
data.isnull().sum(axis=1)
足球运动备受关注,对运动员的个人资料和技艺等方面进行详尽的数据分析意义重大。这有助于教练更深入地掌握球员情况,制定出更有效的战术。同时,也让球迷能更全面地了解自己喜爱的球星。通过运用这些数据集,我们可以深入剖析球员的特点,解答众多疑问。
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
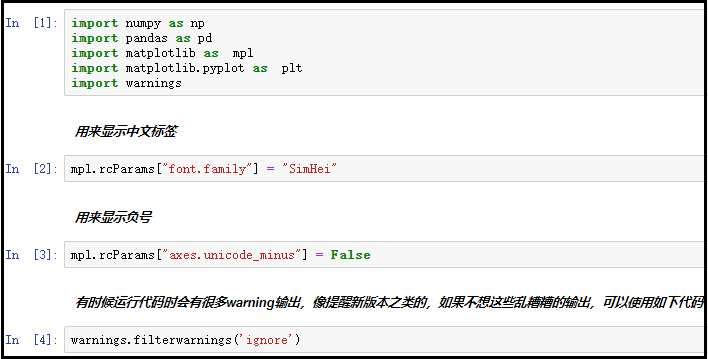
# 用来显示中文标签
mpl.rcParams["font.family"] = "SimHei"
# 用来显示负号
mpl.rcParams["axes.unicode_minus"] = False
# 有时候运行代码时会有很多warning输出,像提醒新版本之类的,如果不想这些乱糟糟的输出,可以使用如下代码
warnings.filterwarnings('ignore')
各国联赛的足球数据形成了一个庞大的体系,内容涉及体能、技术和比赛表现等多个领域。这些数据极为珍贵,经过深入分析,可以发现一些被忽视的球员特点。
data = pd.read_csv("G:\\2大数据学习\\data.csv",engine="python",encoding="utf-8-sig")
熟悉数据
# 查看数据集共有多少行、多少列
data.shape
# 查看数据集的前5行
data.head()
# 查看数据集的后5行
data.tail()
# 随机从数据集中抽取5行,显示
data.sample(5)
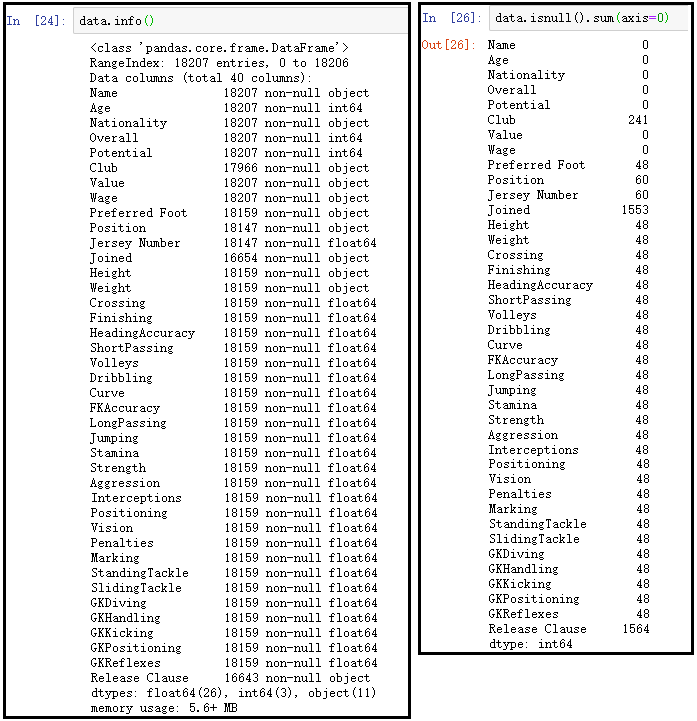
# 显示每列的列名、非空值数量、数据类型,内存占用等信息。
data.info()
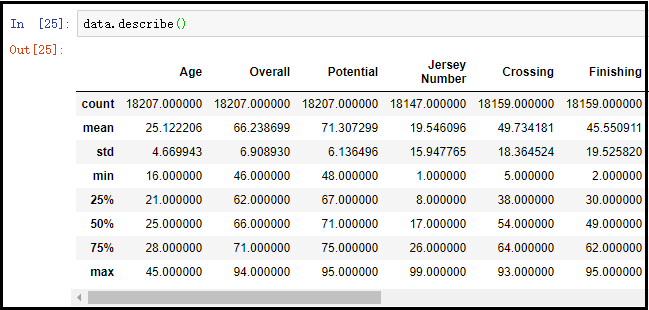
# 此函数可以帮助我们掌握数据的分布情况
data.describe()
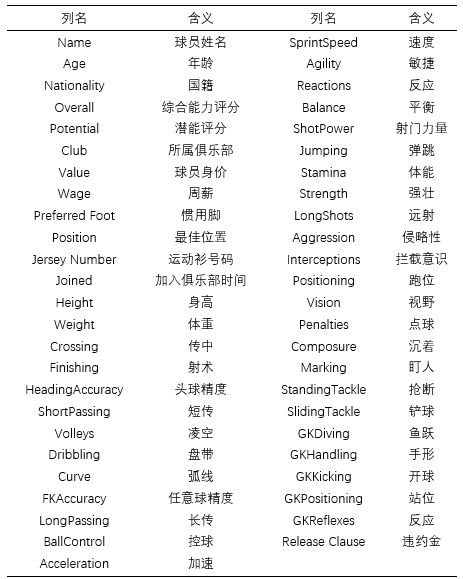
在处理数据之前,首要任务是充分掌握数据。这就像在探索一个不熟悉的城市前,先得查阅地图。只有对数据足够了解,我们的分析才能保持准确。我们必须对数据的构成有全面的认识,比如了解包含哪些字段和记录。
pd.set_option("display.max_columns",500)
columns = ["Name", "Age", "Nationality", "Overall", "Potential", "Club",
"Value", "Wage", "Preferred Foot","Position", "Jersey Number",
"Joined","Height", "Weight", "Crossing","Finishing","HeadingAccuracy",
"ShortPassing", "Volleys","Dribbling", "Curve","FKAccuracy","LongPassing",
"Jumping","Stamina","Strength","Aggression","Interceptions","Positioning",
"Vision","Penalties","Marking","StandingTackle", "SlidingTackle","GKDiving",
"GKHandling","GKKicking","GKPositioning", "GKReflexes", "Release Clause"]
pd.read_csv("G:\\2大数据学习\\data.csv",engine="python",encoding="utf-8-sig",usecols=columns)
# 查看数据集共有多少行、多少列
data.shape
# 查看数据集的前5行
data.head()
# 查看数据集的后5行
data.tail()
# 随机从数据集中抽取5行,显示
data.sample(5)
# 显示每列的列名、非空值数量、数据类型,内存占用等信息。
data.info()
# 此函数可以帮助我们掌握数据的分布情况
data.describe()
进行初步审查,考察数据类别和内容概要。足球运动员的资料包括身高、体重、所属球队和进球记录等。了解每个字段的具体意义及可能值域,这样才能对数据进行分析处理。

缺失值填充
data.info()
data.isnull().sum(axis=0)
处理数据中的空缺情况至关重要。若数据符合正态分布,均值填补是一个不错的选择。以球员的某些体能数据为例,若这些数据呈正态分布,采用均值填补可以确保数据的完整性。
对于这类前后关系紧密的温度数据,使用前后时刻的数据进行填充往往效果更佳。然而,具体情况还需具体分析,不同的数据特性会影响到最适合的填充策略。
data.dropna(axis=0,inplace=True)
data.isnull().sum(axis=0)
异常值检测
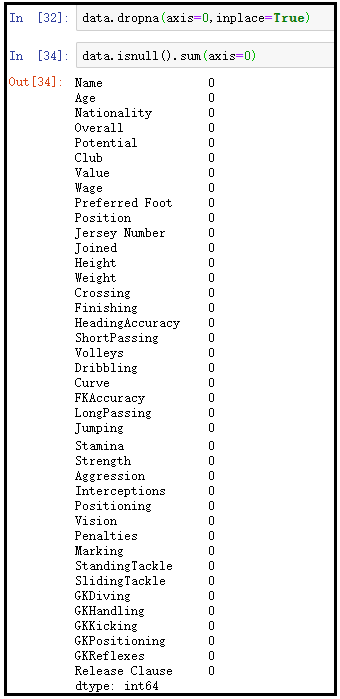
检测异常值有多种途径。依据业务需求与经验确定指标界限,超出此界限的数据便视为异常。比如,若球员的射门成功率显著偏高或偏低,就可能被视为异常情况。
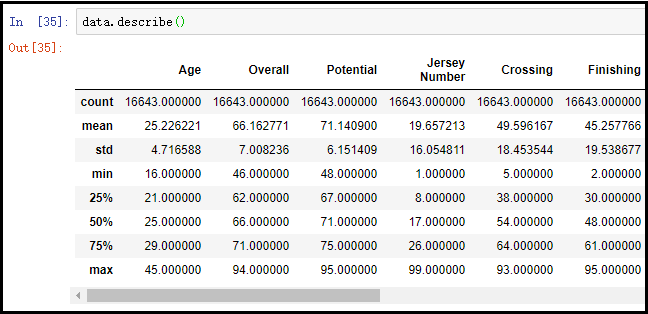
检测异常值对确保数据的精确性至关重要。然而,有些数值虽然显得异常,却可能符合实际情况,因此不能贸然删除。在处理这类问题时,必须结合具体业务情况进行判断。在实际操作中,我们需要灵活运用多种方法来妥善处理。
数据显示与筛选
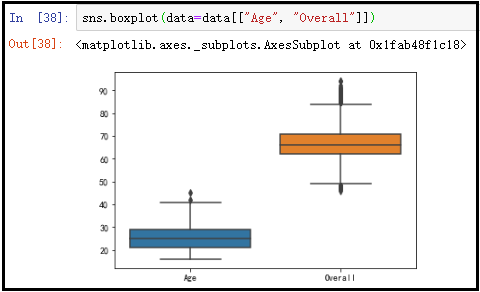
sns.boxplot(data=data[["Age", "Overall"]])
当数据列数较多时,中间部分会进行省略展示。若需查看全部数据,可以调整最大显示列数设置。这样做便于分析者全面掌握情况。
并非所有数据列都需分析,我们可以有选择地加载特征列。例如,若要关注球员的技术水平,只需加载相关技术信息列,这样可以提升分析工作的效率。
data.duplicated().sum()
# data.drop_duplicates(inplace=True)
结果分析与结论
查看字段缺失值可以使用info()方法,但这并不直观。就好比在众多数据中寻找拼图碎片,需要配合其他方法才能准确判断缺失情况。
球员的身高和体重数据使用的是特殊单位,所以在进行处理之前需要将其转换成标准单位。当数据量较大时,这些数据会呈现出正态分布的趋势。然而,球员的出生日期并没有明显的规律性,由于样本量较小,这些微小的差别并不能说明太多问题。将球员的身价和违约金单位统一后,我们可以观察到它们与薪水之间存在线性关系,而且与违约金的关系更为紧密。
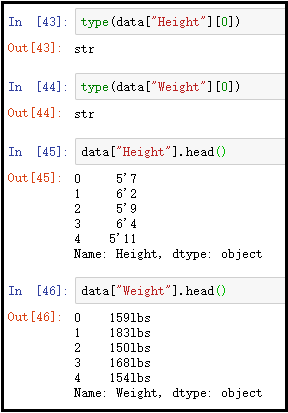
def tran_height(height):
v = height.split("'")
return int(v[0])*30.48 + int(v[1])*2.54
def tran_weight(weight):
v = int(weight.replace("lbs", ""))
return v*0.45
