大数据时代:如何通过机器学习提升用户行为预测的精确性
文章内容
大数据商业模式兴起
当前,大数据备受关注,与之相关的商业模式也日益普及。众多企业开始注重搜集各类信息,目的是为了预判用户行为,并据此作出应对,这已成为市场竞争的核心。以电商平台为例,它们常根据用户的浏览和购买历史来分析其喜好,进而向用户推送相应的商品。
数字化步伐加快,数据的分量愈发明显。所以,众多行业开始采用以数据为基础的决策方式,这一转变正在改变行业间的竞争态势。许多企业正努力探寻数据中的规律,目的是在激烈的市场竞争中保住优势,加强自身的市场地位。
预测的难点与痛点
在机器学习这个领域,准确预测并不算难。然而,要将这些预测与实际业务有效对接,并采取恰当的应对措施,却遇到了不少挑战。这主要是因为业务环境多变又复杂,同时还要应对各种人为的以及非人为因素的干扰。
预测的准确性十分关键。若数据质量不高或信息不完整,这些情况都会对预测模型造成不利影响。比如在金融信贷领域,如果用户的信用信息不完整,那么评估其可能违约的风险就会变得特别困难。
数据预处理的必要性
在构建合适的模型之前,数据清洗这一环节至关重要。在收集数据时,我们常会遇到各种问题,比如噪声、错误和差异等。若不进行清理,这些问题将大大干扰后续的分析和建模过程。
数据集中的连续变量和离散变量需各自进行标准化和因子分析。这样做有助于数据规范化,便于算法深入应用,还能提升预测的精确度。比如,在用户行为分析模型中,对年龄(连续变量)和职业(离散变量)进行相应处理。
不同算法的数据处理
不同机器学习模型对数据的需求各有差异。朴素贝叶斯算法适用于处理离散数据,连续数据则可通过分位数转换变为离散。至于神经网络、支持向量机和最近邻算法,它们需要数据规模保持一致。因子变量可通过one-hot编码处理;而连续变量则需映射至0到1区间,同时保留其分布特性。
随机森林和回归分析可以直接应用于经过因子化的原始数据。在使用过程中,要根据不同的算法对数据进行相应的调整。这样做是为了确保算法的效能得到最大化,同时也能提高模型的表现。
模型训练与调参策略
为了准确衡量模型的效果,我们必须把数据集分成两部分,一部分用来进行模型训练,另一部分则用来检验模型。利用训练数据,我们调整模型参数,预测用户的一些信息,比如是否有过欠费。以电信行业为例,我们可以通过分析用户的通话时间和费用记录等资料来对模型进行训练。
算法种类繁多,各自参数设定各异。以随机森林为例,其参数包括树木数量及每棵树随机选取特征的数量。需对众多参数组合的预测效果进行对比,从中挑选出表现最优异的一组,以此提高模型的整体效能。
不同模型的应用与优化
训练神经网络时,小批量数据能有效减少陷入局部最优的风险。在确定隐藏层数量时,应对不同方案进行细致比较,以挑选出最恰当的方案。另外,采用 Adam 优化算法,针对分类任务,运用加权交叉熵损失函数,可以有效解决数据不平衡的问题。
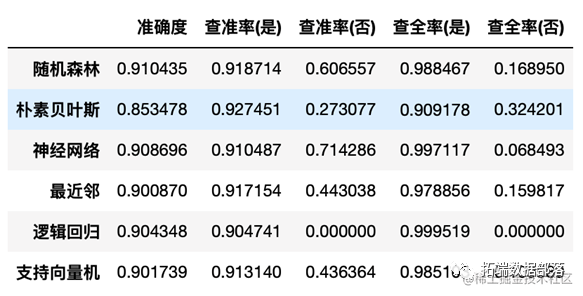
确保分类参数的精确性十分关键,在实施逻辑回归时,必须细致挑选变量,并以 AUC 作为评价依据。对于支持向量回归,我们通过网格搜索来找到最合适的 C 值和核函数。这些策略目的是使模型更符合数据特征,进而提升预测的精确度。

