Echarts图表配置与数据更新技巧:从源码到动态数据插入的完整指南
在网络编程和数据处理领域,往往存在一些小技巧,能让工作效率大大提升。比如说到查找图表,许多人会首先想到从头编写代码,但实际上,直接在官方网站的实例中寻找更为便捷。这个过程看似简单,却常被忽视。只需按照提示调整配置和数据,这种方法非常实用。然而,在这个过程中,也可能会遇到一些挑战。
代码属性不熟悉
初学图表代码时,面对代码中的各种属性确实让人感到困惑。有时修改许久,仍不确定是否正确。这种情况很常见。许多人这时会感到迷茫,但实际上,官网文档是个很好的助手。查阅一下,就能明白这些属性的含义和用法,这是解决这类问题的最直接有效方法。我自己也试过,遇到不懂的属性就查阅文档,渐渐地就熟悉了。这样做不仅提高了工作效率,还让我更深入地理解了代码的工作机制。
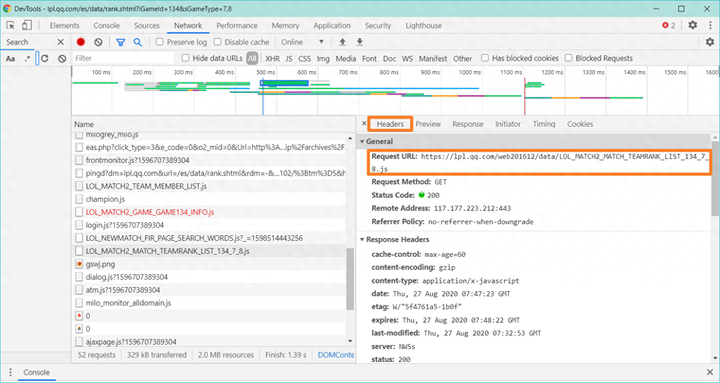
数据获取方式
import requests
def get_info(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'}
response = requests.get(url=url,headers=headers)
return response.text
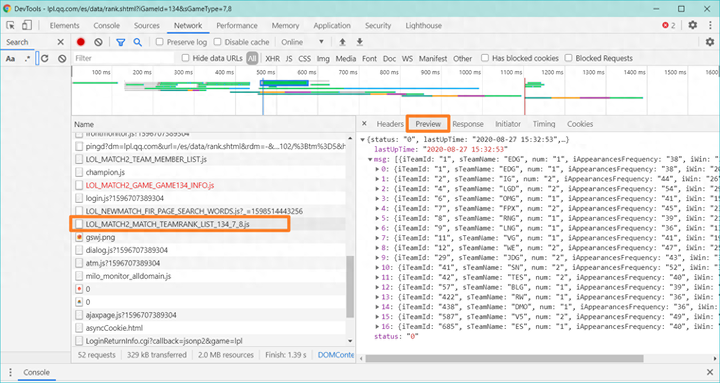
info = get_info('https://lpl.qq.com/web201612/data/LOL_MATCH2_MATCH_TEAMRANK_LIST_134_7_8.js')
print(info)
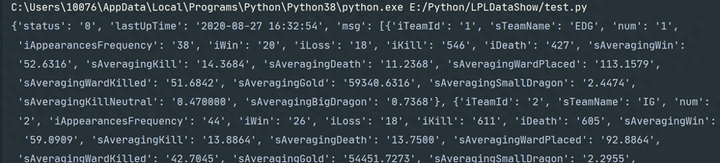
曾尝试借助第三方库来控制浏览器获取信息。起初,觉得这是个不错的主意,便着手编写代码。编写过程中,感觉挺顺畅。然而,运行时发现速度极慢,这在数据处理上是个大问题。于是,重新编写了爬虫程序。再次运行后,速度明显提升。之前获取数据需20秒,现在仅需2秒。这对比明显,让人意识到正确方法的重要性。
import requests
import json
def get_info(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'}
response = requests.get(url=url,headers=headers)
return response.text
info = get_info('https://lpl.qq.com/web201612/data/LOL_MATCH2_MATCH_TEAMRANK_LIST_134_7_8.js')
info = json.loads(info) #将str对象转换为dict(字典)对象
info_msg = info['msg'] #使用字典里面的键获取对于的值
#队名
teamName = [data['sTeamName'] for data in info_msg]
#出场次数
out_count = [data['iAppearancesFrequency'] for data in info_msg]
#胜场
win = [data['iWin'] for data in info_msg]
#败场
loss = [data['iLoss'] for data in info_msg]
#胜率
win_rate = [int(str((int(data['iWin'])/(int(data['iWin'])+int(data['iLoss'])))*100)[:2]) for data in info_msg]
#总击杀
kill_sum = [data['iKill'] for data in info_msg]
#总死亡
death_sum = [data['iDeath'] for data in info_msg]
#插眼
placed_eye = [int(float(data['sAveragingWardPlaced']))for data in info_msg]
#排眼
killed_eye = [int(float(data['sAveragingWardKilled']))for data in info_msg]
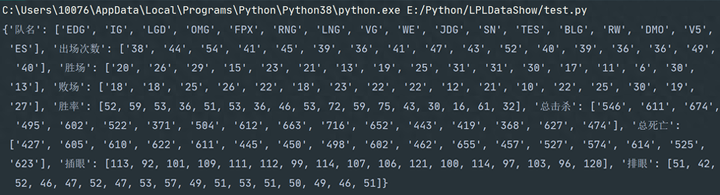
infos_list = [('队名',teamName),('出场次数',out_count),('胜场',win),
('败场',loss),('胜率',win_rate),('总击杀',kill_sum),
('总死亡',death_sum),('插眼',placed_eye),('排眼',killed_eye)]
info_dict = {key:value for key,value in infos_list}
print(info_dict)
数据类型转换
获取战队信息后,你会看到它经过json格式化处理。此时,数据形式为字符串。但通常我们更希望它是字典形式。这时,就需要使用json.loads()函数进行转换。这一操作至关重要,否则后续数据处理会变得麻烦。使用该函数后,数据便可根据需求操作。这是众多编程者常用的技巧之一。

推导式优化
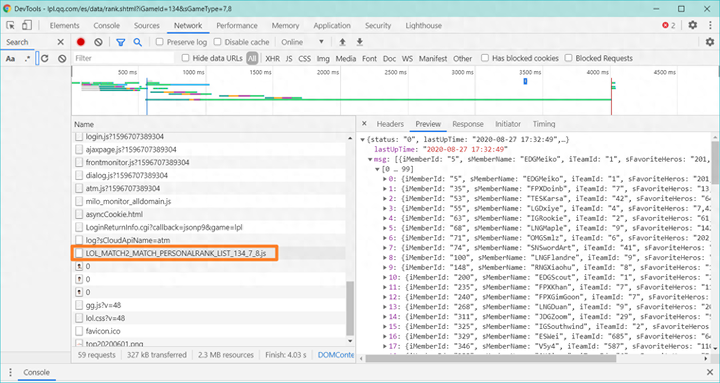
编写程序时,我们都追求代码的简洁与高效。比如在数据处理环节,列表和字典推导式经常被用到。我用这些推导式轻松获取了所需数据。我发现列表推导式还有更简便的写法。在源码的【.py】文件里,第125行就展示了这种优化后的代码。而117到122行则是未优化的版本,带有注释,仿佛藏着一个等待大家探索和学习的惊喜。
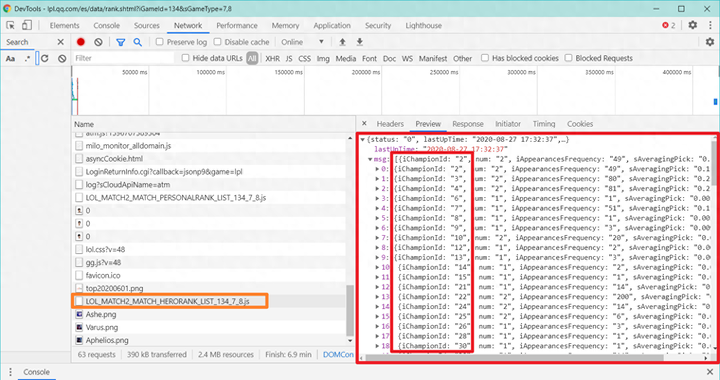
数据匹配问题
数据获取往往充满挑战。比如,数据从两个不同接口获取后,还需思考如何将数据与相应名称对应。这确实是个难题。在此,我不详述数据获取的具体过程,大家可查阅源码。关键在于如何准确匹配英雄名称,这需要运用特定的逻辑判断和数据处理技巧,同时也与数据库操作相关。
name = []
for i in hero_key_id_top60:
for j in hero_name_id_list:
if i == j :
#由于从lpl数据页面无法获取到英雄名称,只能获取到对应的id
#一层循环是pick率前60的英雄id,二层是所有英雄的的id
#通过if判断,将pick率前60的英雄写入到指定列表中
name.append(hero_name_list[hero_name_id_list.index(j)])

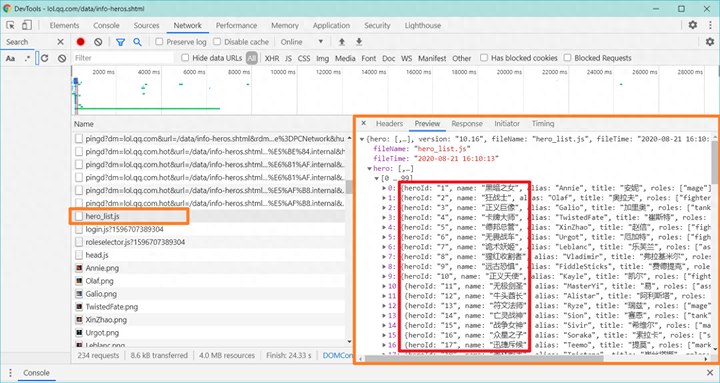
数据库与Ajax部分
首先,在电脑上建立一个叫做【lpl】的数据库,但别急于创建表格。接下来,需要连接这个数据库。记得将代码中的密码部分替换成你自己的。如果你对相关代码不熟悉,建议先学习MySQL。此外,还有一个常见问题需要注意,那就是在HTML文件引用外部文件时,文件路径必须进行修改。Ajax技术与XML有关,它能向服务器发送请求,接收并处理json格式的数据,以此来实现网页的局部更新。其主要作用是获取和整理数据,将其保存为字典形式,然后转换为json对象返回。具体实现方法可以参考【js.js】文件的第359行。


当图表需要用到这些数据时,处理方式大多一致。首先,在【app.py】中设立路由并返回数据,接着在【js.js】中编写与Ajax相关的脚本。现在我想了解一下,在处理数据时,大家是否遇到过类似的问题,又是如何解决的?期待大家的评论和交流,不妨点赞并转发这篇文章。
